


softmax多分类实现
softmax多分类回归
softmax各个样本分量之和为1。
当只有两个类别时,与对数几率回归完全相同。
softmax的交叉熵损失函数
在tf.keras中使用categorical_crossentropy和sparse_categorical_crossentropy来计算softmax交叉熵
Fashion MNIST数据集
Fashion MNIST的作用是成为经典MNST数据集的简易替
换。
MNST数据集包含手写数字(0、1、2等)的图像,这些图
像的格式与Fashion MNIST使用的服饰图像的格式相同。
Fashion MNIST比常规MNST手写数据集更具挑战性。
这两个数据集都相对较小,用于验证某个算法能否如期正常
运行。它们都是测试和调试代码的良好起点。
Fashion MNIST数据集包含70000张灰度图像,涵盖10
个类别。
我们将使用60000张图像训练网络。并使用10000张图像
评估经过学习的网络分类图像的准确率。
可以从 TensorFlow直接访问 Fashion MNIST,只需导入和
加载数据即可。
链接:数据集链接
提取码:6666
将Fashion MINST 放在C:/用户/你的用户名/.keras/datasets 目录下
学习速率
学习速率是一种超参数或对模型的一种手工可配置的设置
需要为它指定正确的值。如果学习速率太小,则找到损失函
数极小值点时可能需要许多轮迭代;如果太大,则算法可能
会“跳过”极小值点并且因周期性的“跳跃”而永远无法找
到极小值点。
反向传播算法
反向传播算法是一种高效计算数据流图中梯度的技术
每一层的导数都是后一层的导数与前一层输出之积,这正是
链式法则的奇妙之处,误差反向传播算法利用的正是这一特
点。
前馈时,从输入开始,逐一计算每个隐含层的输出,直到输
出层。
然后开始计算导数,并从输出层经过各隐含层逐一反向传播。
为了减少计算量,还需对所有已完成计算的元素进行复用
这便是反向传播算法名称的由来。
常见的优化函数
优化器( optimizer)是编译模型的所需的两个参数之一。
你可以先实例化一个优化器对象,然后将它传入
model. compile0,或者你可以通过名称来调用优化器。在
后一种情况下,将使用优化器的默认参数。
SGD:随机梯度下降优化器
随机梯度下降优化器SGD和min-batch是同一个意思,抽取
m个小批量(独立同分布)样本,通过计算他们平梯度均值。
RMSprop
经验上, RMSProp被证明有效目实用的深度学习网络优化算法
RMSProp增加了一个衰减系数来控制历史信息的获取多
RMSProp会对学习率进行衰减。
Adam优化器
- Adam算法可以看做是修正后的 Momentum+ RMSProp算
法. - Adam通常被认为对超参数的选择相当鲁棒
- 学习率建议为0.001
Adam是一种可以替代传统随机梯度下降过程的一阶优化算
法,它能基于训练数据迭代地更新神经网络权重。
Adam通过计算梯度的一阶矩估计和二阶矩估计而为不同的
参数设计独立的自适应性学习率。
如何提高网络的拟合能力
一种显然的想法是增大网络容量:
- 增加隐藏层深度
- 增加隐藏神经元个数
这两种方法哪种更好呢?
单纯的增加神经元个数对于网络性能的提高并不明显,
而增加层会大大提高网络的拟合能力
这也是为什么现在深度学习的层越来越深的原因。
单层的神经元个数,不能太小,太小的话,会造成信息
瓶颈,使得模型欠拟合。
dropout防止过拟合
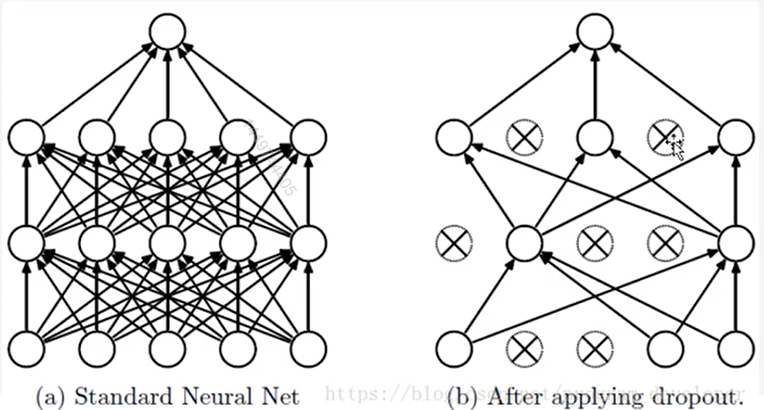
为什么说 Dropout可以解决过拟合?
- 取平均的作用:我们用相同的训练数据去训陈5个不同的神经网络,一般
会得到5个不同的结果,此时我们可以采用“5个结果取
均值”或者“多数取胜的投票策略″去决定最终结果。 - 减少神经元之间复杂的共适应关系:因为 dropout
程序导致两个神经元不一定每次都在一个 dropout网络中
出现。这样权值的更新不再依赖于有固定关系的隐含节
点的共同作用,阻止了某些特征仅仅在其它特定特征下
才有效果的情况。
构建网络的总原则
- 增大网络容量直到过拟合
- 采取措施抑制过拟合 (dropout、正则化、图像增强、加大数据集、交叉验证)
- 继续增大网络容量直到过拟合
实现
import tensorflow as tf
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
# 在jupyter notebook中使用,使结果直接输出在控制台中
# %matplotlib inline
(train_image,train_label),(test_image,test_label) = tf.keras.datasets.fashion_mnist.load_data()
# 数据归一化
train_image = train_image/255
test_image = test_image/255
model = tf.keras.Sequential()
# 数据扁平化
model.add(tf.keras.layers.Flatten(input_shape=(28,28)))
model.add(tf.keras.layers.Dense(32, activation='relu'))
model.add(tf.keras.layers.Dense(10,activation='softmax'))
model.compile(
optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['acc']
)
history = model.fit(train_image,train_label,epochs=30,validation_data=(test_image,test_label))
# 绘制loss函数折线图
plt.plot(history.epoch,history.history.get('loss'),label='loss')
plt.plot(history.epoch,history.history.get('val_loss'),label='val_loss')
plt.legend()
# 绘制acc折线图
plt.plot(history.epoch,history.history.get('acc'),label='acc')
plt.plot(history.epoch,history.history.get('val_acc'),label='val_acc')
plt.legend()
# 转换独热编码
train_label_onehot = tf.keras.utils.to_categorical(train_label)
test_label_onehot = tf.keras.utils.to_categorical(test_label)
model = tf.keras.Sequential()
# 数据扁平化
model.add(tf.keras.layers.Flatten(input_shape=(28,28)))
model.add(tf.keras.layers.Dense(128, activation='relu'))
model.add(tf.keras.layers.Dense(10,activation='softmax'))
model.compile(
optimizer='adam',
loss='categorical_crossentropy',
metrics=['acc']
)
model.fit(train_image,train_label_onehot,epochs=5)
predict = model.predict(test_image)
# 预测结果 9
np.argmax(predict[0])
# label对应结果也是9
test_label[0]
评论区